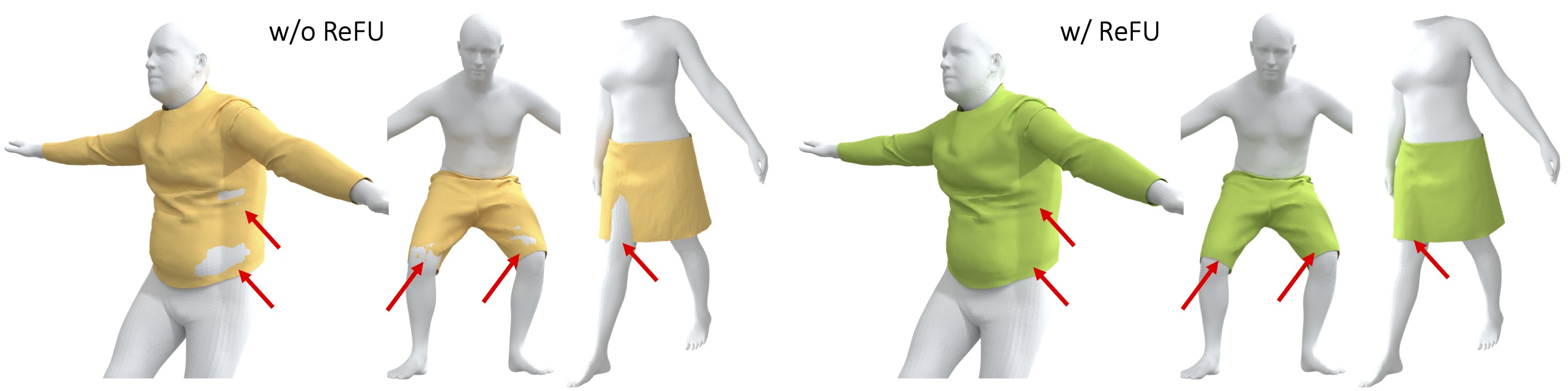
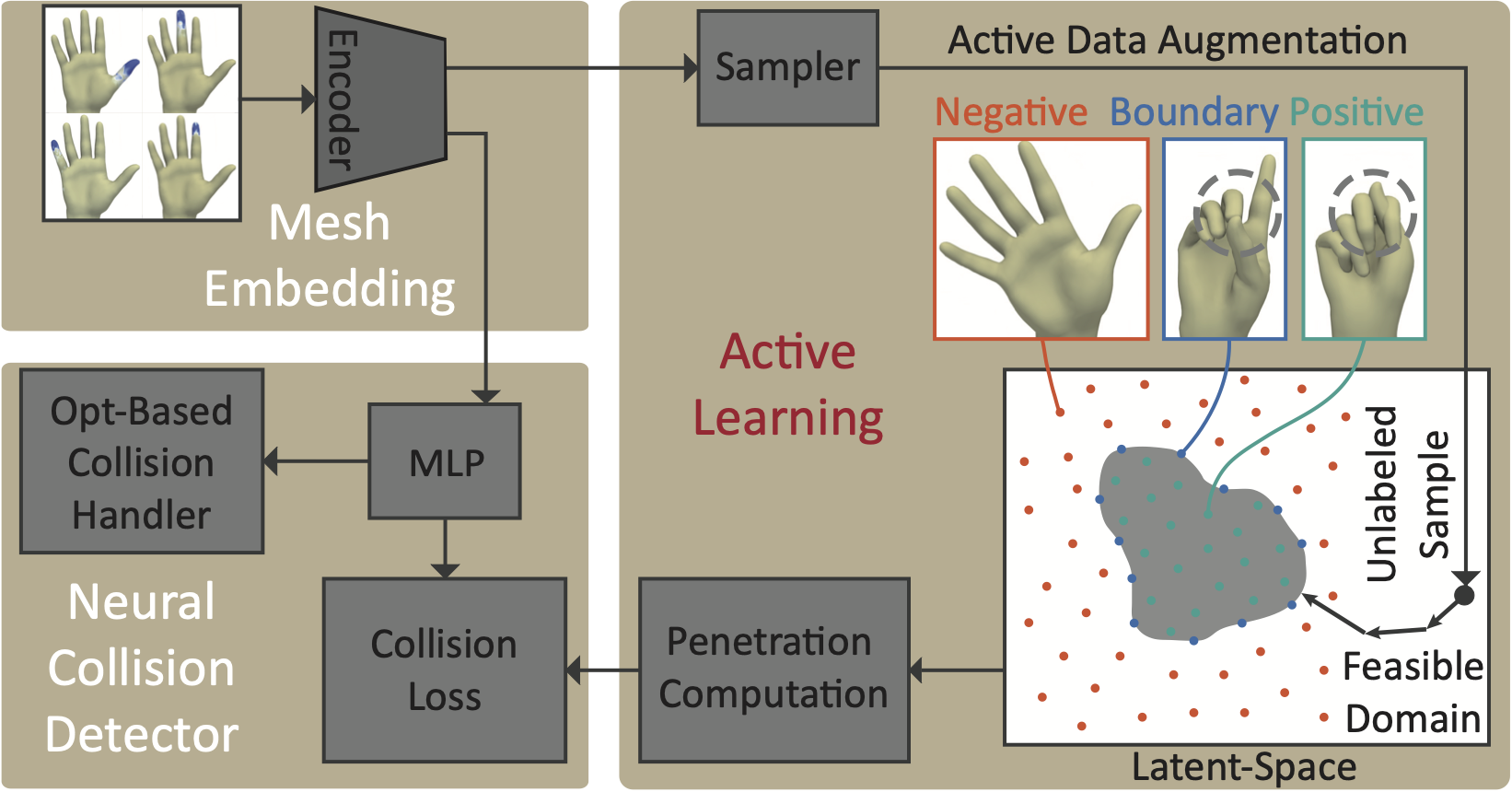
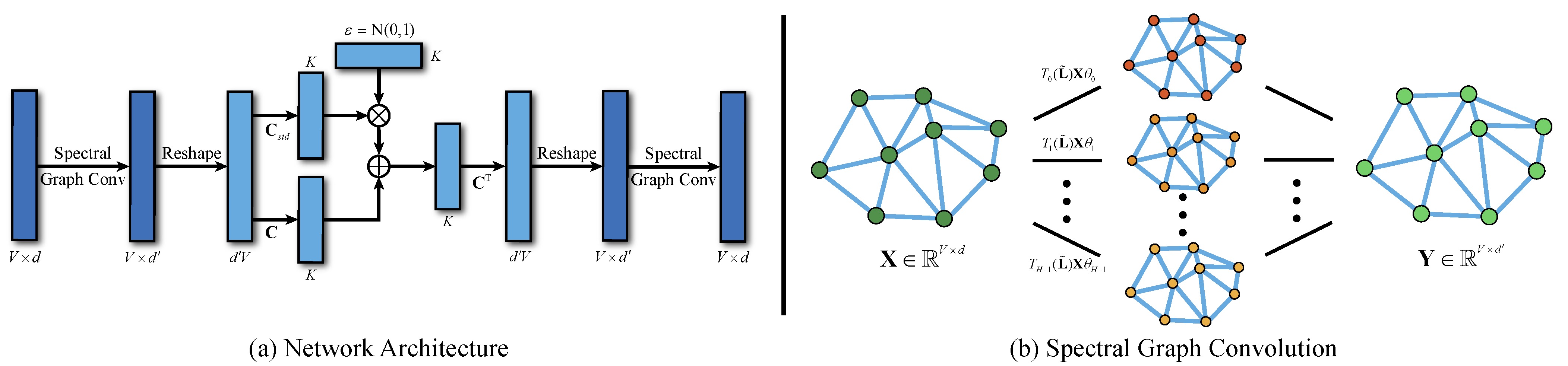
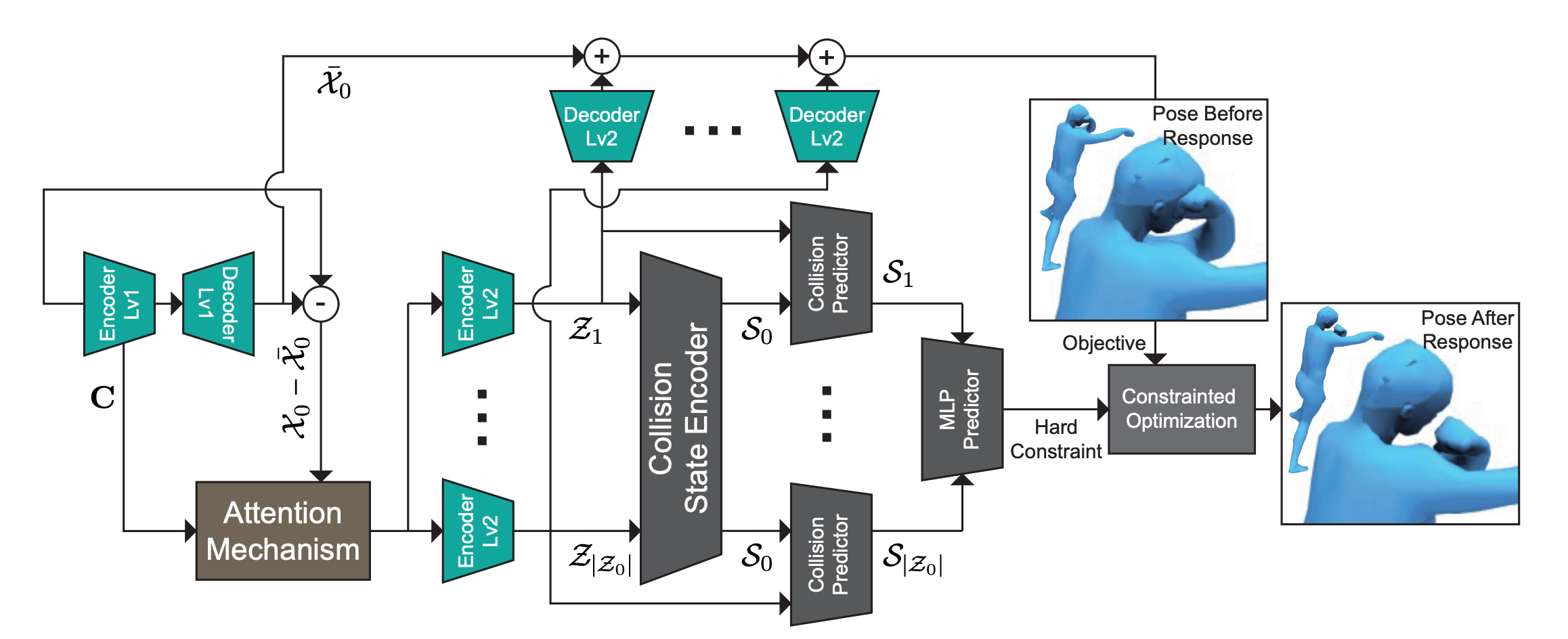
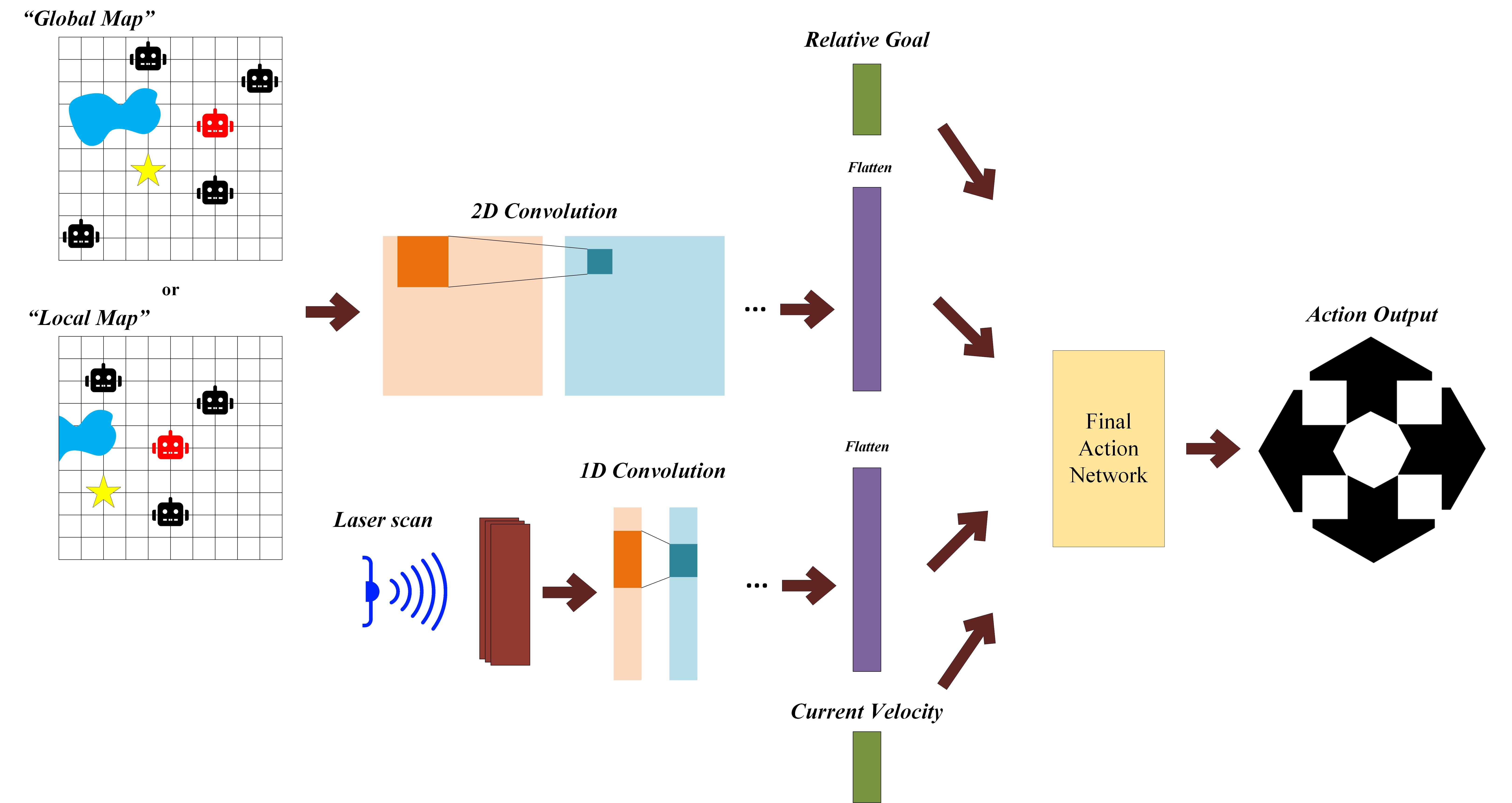
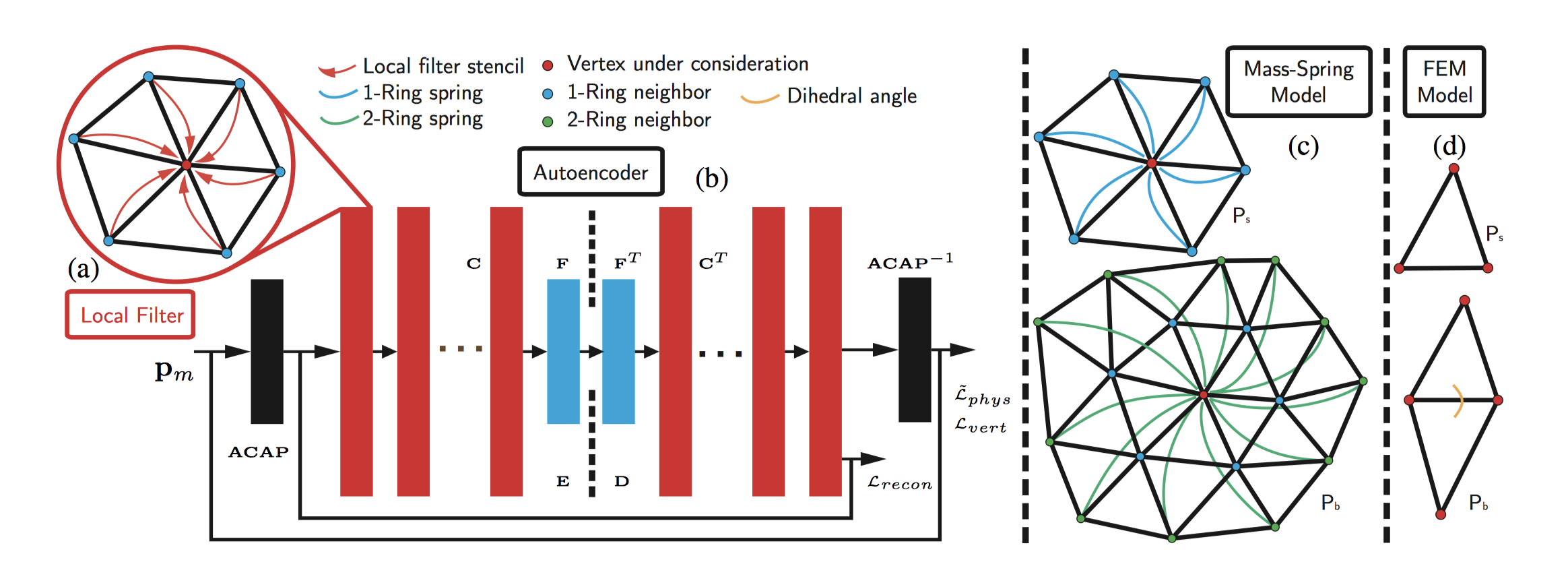
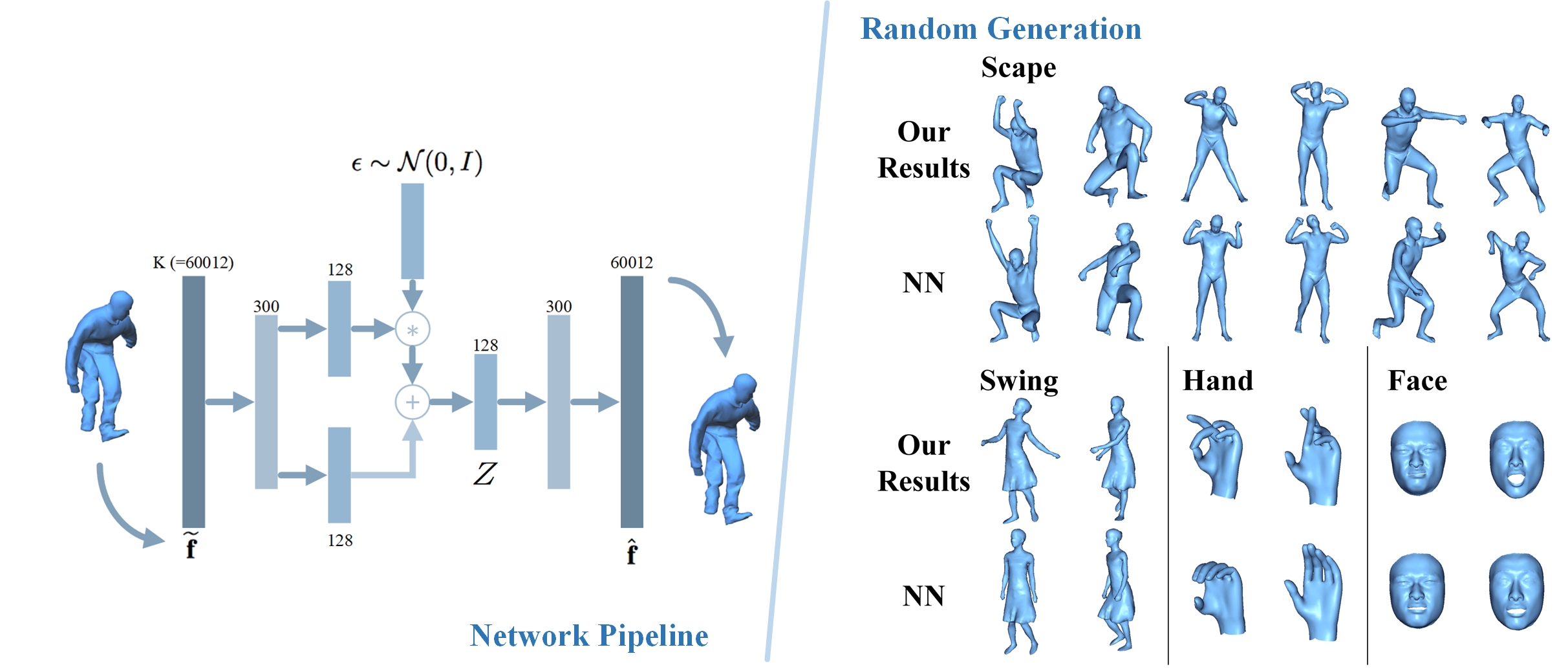
I am Qingyang Tan, a Research Scientist at Meta Reality Labs. I obtained my Ph.D. degree the University of Maryland, College Park advised by Prof. Dinesh Manocha. I received a B.Eng. degree in Computer Science and Technology from the University of Chinese Academy of Sciences.
In the 2022 summer, I interned in Adobe Research, advised by Dr. Noam Aigerman. In the 2021 summer, I interned in Adobe Research, advised by Dr. Yi Zhou, Dr. Tuanfeng Y. Wang, Dr. Duygu Ceylan and Dr. Xin Sun. In the 2020 summer, I interned in Facebook Reality Lab, advised by Dr. Takaaki Shiratori and Dr. Breannan Smith.
I conducted my undergraduate thesis in VIPL Group at the Institute of Computing Technology (ICT), Chinese Academy of Sciences (CAS), under the supervision of Prof. Xilin Chen and Prof. Xiujuan Chai. Before that, I interned in Human Motion Research Group at ICT, CAS, supervised by Prof. Lin Gao, Prof. Yu-Kun Lai and Prof. Shihong Xia. I also have several research experiences in interdisciplinary science, including UROP projects in Institute of Medical Engineering & Science and MIT Sloan School of Management of MIT, and synthetic biology project for the International Genetically Engineered Machine (iGEM) competition.
Here is my resume. Please feel free to contact me.
Interests
- Computer Graphics
- Physical Simulation
- Geometry Processing
- Computer Vision
- Machine Learning
Education
-
Ph.D. in Computer Science, 2018-2023
University of Maryland, College Park
-
B.Eng. in Computer Science and Technology, 2014-2018
University of Chinese Academy of Sciences
-
Special Student in EECS, 2017
Massachusetts Institute of Technology