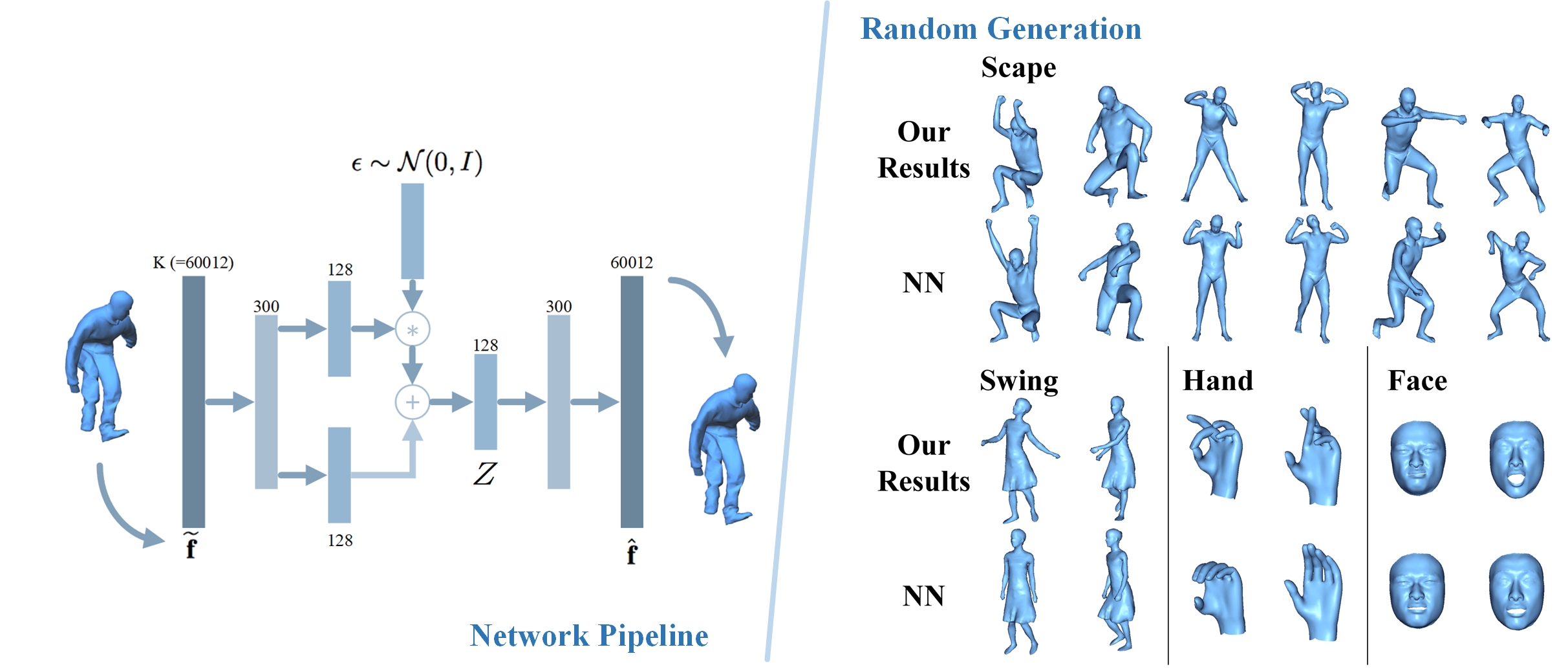
 Pipeline of mesh VAE and random generation results.
Pipeline of mesh VAE and random generation results.
Abstract
3D geometric contents are becoming increasingly popular. In this paper, we study the problem of analyzing deforming 3D meshes using deep neural networks. Deforming 3D meshes are flexible to represent 3D animation sequences as well as collections of objects of the same category, allowing diverse shapes with large-scale non-linear deformations. We propose a novel framework which we call mesh variational autoencoders (mesh VAE), to explore the probabilistic latent space of 3D surfaces. The framework is easy to train, and requires very few training examples. We also propose an extended model which allows flexibly adjusting the significance of different latent variables by altering the prior distribution. Extensive experiments demonstrate that our general framework is able to learn a reasonable representation for a collection of deformable shapes, and produce competitive results for a variety of applications, including shape generation, shape interpolation, shape space embedding and shape exploration, outperforming state-of-the-art methods.
Qingyang Tan
Ph.D. Candidate
My research interests include computer graphics, physical simulation, geometry processing,, computer vision, and machine learning.